Why Precision Beats Speed in AI-Driven Organisations
88% of organisations now use AI in at least one business function. Fewer than 6% generate meaningful financial impact from it. That gap has a name. It is a thinking problem.
Fast Is Not the Problem. Undirected Is.
Picture a team twelve months into an AI programme. The tools are live. The demos were impressive. Leadership pointed to the initiative in the annual report. The AI team is genuinely capable. The P&L shows nothing.
This is the most common story in enterprise AI right now, and it is playing out with remarkable consistency across industries and geographies. In the UK, 88% of business leaders plan to increase AI investment in the next twelve months. Only 7% of UK firms have a strategic, enterprise-wide AI plan. 42% describe their current AI investment as piecemeal.
The pattern beneath these numbers is consistent. Organisations deploy AI horizontally before establishing vertical wins. They install tools without redesigning the workflows those tools sit inside. They launch department-led pilots that produce compelling proofs-of-concept and inconclusive business results. Nearly 70% of Fortune 500 companies now use Microsoft 365 Copilot. 40% of workers find it helpful. The benefits spread thinly across employees and disappear before they reach a balance sheet.
Lloyds Banking Group made a different decision with the same tool. When offered early access to Copilot licences, they required every department to submit a business case with measurable goals before a single licence was issued. They started with 300. Once the evidence was sufficient, they scaled to 40,000. A process that had taken 65 hours became a 30-hour one. The tool was identical. The discipline around it was not.
Speed is a symptom here, not the cause. The cause is directionlessness. Organisations moved because the pressure to move was real. The question of where to move, and why, and toward what precise outcome, came second. In most cases it never came at all.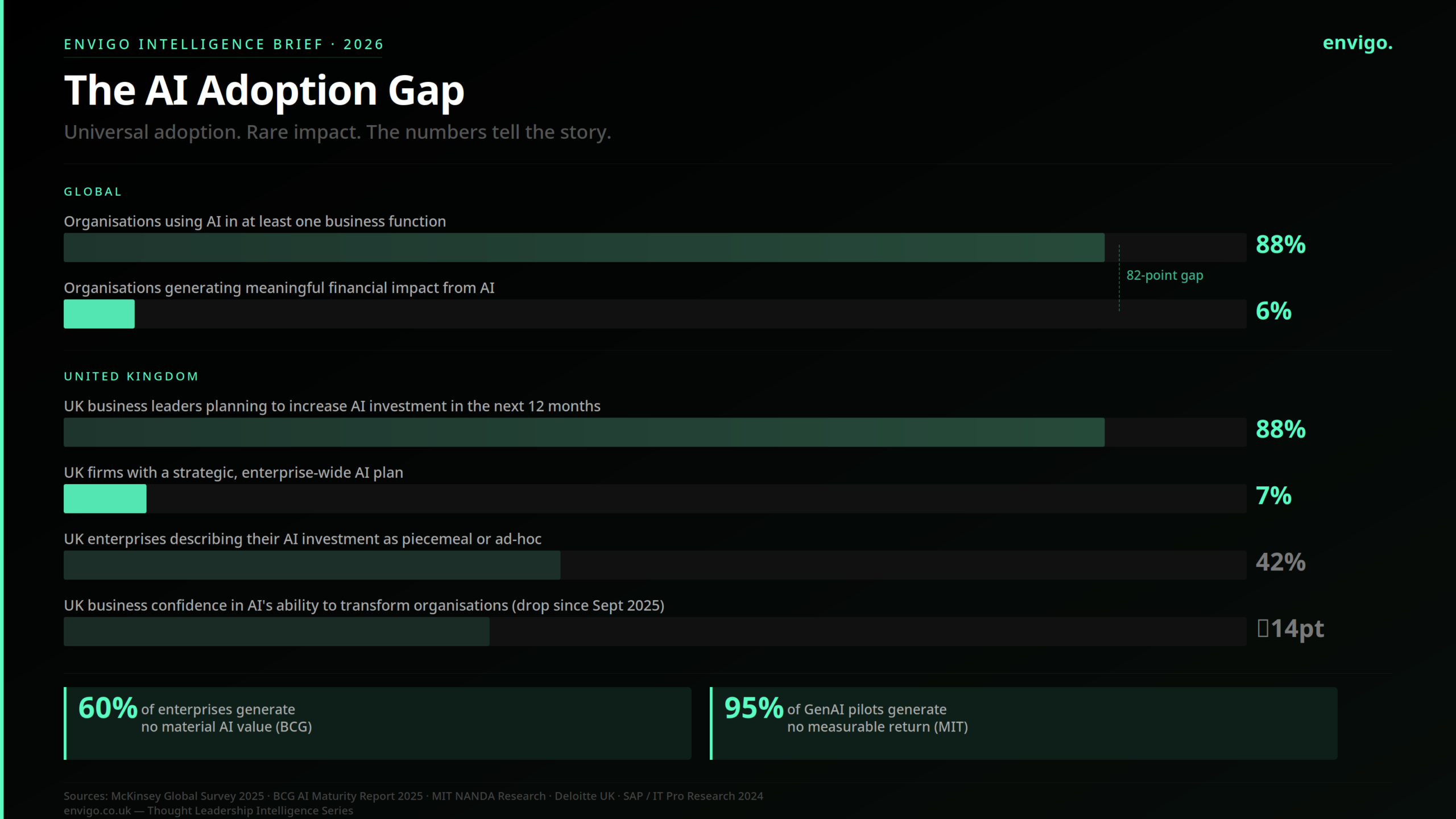
The System Will Answer Any Question You Give It. Including the Wrong One.
AI does not fail by producing wrong answers. It fails by producing confident, complete, well-structured answers to questions that should never have been asked. This is what makes it genuinely different from previous enterprise software. A spreadsheet formula built on wrong inputs produces a wrong number. It does not produce a 2,000-word strategic recommendation that looks indistinguishable from the right one.
The IBM Watson for Oncology programme is the clearest documented example of this mechanism at scale. IBM had genuine capability. The NLP architecture was advanced. The intention was serious. The failure was not technical. It was a question failure.
IBM asked: how do we make the expertise of elite oncologists available to every hospital in the world? That question produced Watson for Oncology. The system was trained on hypothetical patient cases created by a small group of oncologists at Memorial Sloan Kettering, an elite institution with resources, drug availability, and clinical infrastructure most hospitals globally do not share. When deployed in Thailand, South Korea, and India, Watson recommended treatments that violated local clinical guidelines, exceeded local drug availability, and reflected the treatment preferences of a specific group of doctors at a single American institution rather than the reality of the patient in front of the physician.
The question IBM should have asked was different: what prevents a skilled oncologist in a resource-constrained setting from making the best possible decision for this specific patient today? That question has a different answer. Watson answered the first one with precision and at scale. Hospitals spent years and significant capital implementing a system that senior oncologists summarised in a single sentence to IBM executives: you are not telling me anything I do not already know.
IBM’s $4 billion write-down in the Watson Health division was the financial consequence of a question that was well-answered and wrong.
The mechanism appears at every scale. A consumer brand noticed declining average order value and asked AI how to increase it. The system delivered excellent answers: bundling strategies, upsell architecture, promotional sequencing. AOV improved temporarily. Customer engagement and margin continued their decline. The correct question was what was eroding trust in the product. The AI was never given the opportunity to answer it.
AI amplifies the direction of the question it receives. When the question is precise, the output compounds. When the question is imprecise, the output is confidently, completely, expensively wrong.
The 5% Made Different Structural Decisions.
The organisations generating real, compounding value from AI are built differently. The distinction is not cultural or attitudinal. It is architectural. Five structural decisions separate them from the rest.
Use cases begin with a documented cost baseline. Before a model is selected, high-performing organisations require a clear answer to one question: what does this problem cost us today, expressed as a number, assuming AI is never deployed? This baseline is not a formality. It is the only mechanism by which success can later be measured and failure can be caught early. Organisations that skip this step have no way of knowing whether their AI initiative is working. They measure activity instead.
Data readiness receives the majority of the budget before deployment begins. Research from enterprise AI programmes that consistently clear failure statistics shows a consistent pattern: 50 to 70% of the timeline and budget is allocated to data extraction, normalisation, governance, and quality validation before a single model is selected. Most organisations invert this ratio. They acquire the model and then discover that the data feeding it is inconsistent, unstructured, or ungoverned. The model performs poorly. The conclusion drawn is that AI did not work. The correct conclusion is that the data infrastructure was never built.
Workflows are redesigned before AI is embedded. High-performing organisations are three times as likely as peers to have fundamentally redesigned individual workflows as a prerequisite to AI deployment. AI does not improve a process. It accelerates what the process already does. A manual, fragmented claims workflow does not become efficient because a model sits inside it. It becomes a faster, more scalable version of the same fragmentation. Redesign is not a technical task. It is a strategic one, and it belongs before the technical work begins.
Governance structures make AI outcomes measurable at the initiative level. In organisations where AI is generating compounding returns, accountability for business outcomes is built into the architecture of the programme. Every initiative has a defined financial metric, an owner of that metric, and a review cadence tied to it. This is not a management style. It is a system design decision. The result is that AI teams are accountable to outcomes rather than outputs, and leadership has visibility into which initiatives are working before costs compound on the ones that are not.
AI is embedded into operational architecture. The organisations ahead in AI are not ahead because they have better models. They are ahead because their AI systems sit inside live operations and learn continuously from real decisions. Tools installed alongside a workflow do not accumulate institutional knowledge. Systems embedded within it do. The knowledge gap this creates between leaders and followers widens with every passing quarter.
Two Organisations. One Principle. Decades Apart.
Rolls-Royce began using AI for engine health monitoring in 1999. The programme did not begin with a technology decision. It began with a precise commercial question: how do we make unplanned engine failure a commercial impossibility for our customers, and structure our business so that we are financially rewarded only when our engines are reliably operating?
The AI followed the question. Modern Rolls-Royce engines track over 10,000 parameters in real time during flight. The system prevents approximately 400 unplanned maintenance events across the fleet each year. TotalCare, the service model this capability underpins, is now a multi-billion pound component of the business. Every new engine sold under a TotalCare contract adds to a proprietary dataset that has been compounding for 26 years. The competitive advantage is structural and widening.
JP Morgan’s COiN system began with a question of identical precision: how do we process 12,000 commercial credit agreements annually without committing 360,000 hours of legal review time to do it? The question defined the problem. The AI answered the specific problem that was asked. JP Morgan now tracks the financial benefit of every AI initiative before it goes into production and after, with a financial discipline that produces 30 to 40% annual growth in measurable AI-attributed value. The LLM Suite deployed to over 200,000 employees followed the same discipline: defined outcomes, measurable baselines, and governance built before deployment.
In both cases, the technology was consequential. In both cases, it was the second decision. The question came first.
Seven Questions. If You Cannot Answer All of Them, You Are Not Ready.
These are diagnostic instruments. They are worth running against every AI initiative currently live in your organisation, and against every one under consideration.
| 1. What is the cost of this problem without AI? If this cannot be answered precisely, the initiative has no financial baseline. Progress cannot be measured against a number that was never established. |
| 2. What precise question are we asking the AI to answer? The problem and the question are different things. IBM’s problem was democratising oncology expertise. The question they asked was how to replicate elite physician preferences at scale. The distinction cost them four billion dollars and, more importantly, produced a system that harmed the patients it was built to help. |
| 3. What does success look like in 90 days, expressed as a single number? Goals that are not specific enough to be wrong are not specific enough to be right. Vague targets produce vague programmes and uninterpretable results. |
| 4. Is the workflow this AI sits inside redesigned, or only augmented? The answer to this question determines whether the AI is compounding the value of a well-designed process or accelerating the cost of a broken one. |
| 5. Who owns the outcome, as distinct from the tool? Tools require owners. Outcomes require different owners. When these roles are held by the same team, the incentive is to report on tool performance rather than business impact. |
| 6. What is the data governance structure that makes this work? The organisations winning with AI spent the majority of their programme budget on this question before selecting a model. Trustworthy, well-governed data is the infrastructure that makes every other decision meaningful. |
| 7. How does this compound over time? A system that learns from every decision it informs becomes more valuable with use. A tool that processes inputs and produces outputs holds the same value it had on day one. The former builds competitive advantage. The latter represents a cost. |
The tools required to deploy AI at enterprise scale are widely available. The thinking required to deploy them precisely is considerably rarer. The organisations that will define the next decade of enterprise AI are the ones that understood this distinction before they made their first deployment decision and built their programmes around it. The competitive gap being established right now is a gap in the quality of questions being asked, and it will be difficult to close once it compounds.
Sources: McKinsey Global Survey on AI 2025 · BCG AI Maturity Report 2025 · MIT NANDA Research · IBM Institute for Business Value · Deloitte UK · SAP/IT Pro Research 2024 · JP Morgan Annual Report 2024 · Rolls-Royce Engineering Division · STAT News · S&P Global AI Adoption Study 2025
Where to go next
If you’re dealing with comparable constraints, we’re open to a conversation.